Edit: I have since completed a successful Metrocluster Failover Test and it is documented in full in the following blog posts:
- NetApp 7-Mode MetroCluster Disaster Recovery – Part 1
- NetApp 7-Mode MetroCluster Disaster Recovery – Part 2
- NetApp 7-Mode MetroCluster Disaster Recovery – Part 3
Just before the Xmas break I had to perform a Metrocluster DR test. I don’t know why all DR tests need to be done just before a holiday period, it always seems to happen that way. Actually I do know but it doesn’t make the run up to the holidays any more comfortable for an IT engineer. Before I began the DR test I had a fairly OK knowledge of how MetroCluster worked but afterwards it’s definitely vastly improved. If you want to learn how MetroCluster works and how it can be fixed I’d recommend breaking your environment and work with NetApp support to fix it again. Make sure to put aside quite a bit of time so that you can get everything working again and your learning experience will be complete. (You may have problems convincing your boss to let you break your environment though). I haven’t worked with MetroCluster before so while I understood how it worked and what it could do I really didn’t understand the ins-and-outs and how it is different to a normal 7-Mode HA-cluster. The short version is that it’s not all that different but it is far more complex when it comes to takeovers and givebacks and just a bit more sensitive also. During my DR test I went from a test to an actual DR and infrastructure fix. Despite the problems we faced the data management and availability was rock solid and we suffered absolutely no data loss.
I won’t go deeply into what MetroCluster is and how it works here, I may cover that in a separate blog post, but the key thing to be aware of is that the aggregates are classed as Plexes and use SyncMirror to ensure that all writes in a primary Plex gets synchronously written to the secondary Plex so that all data exists in to places. SyncMirror differs from SnapMirror by synchronizing the aggregrates whereas SnapMirror occurs at the volume level. MetroCluster itself is classed as a disaster avoidance system and satisfied this by having multiple copies of synchronised data on different sites. The MetroCluster in our environment is part of a larger Flexpod environment which includes fully redundant Cisco Nexus switches, Cisco UCS chassis and blades and a back-end dark fibre network between sites. A 10,000 foot view of the environment looks something like the below diagram and I think you can agree that there are a lot of moving parts here.
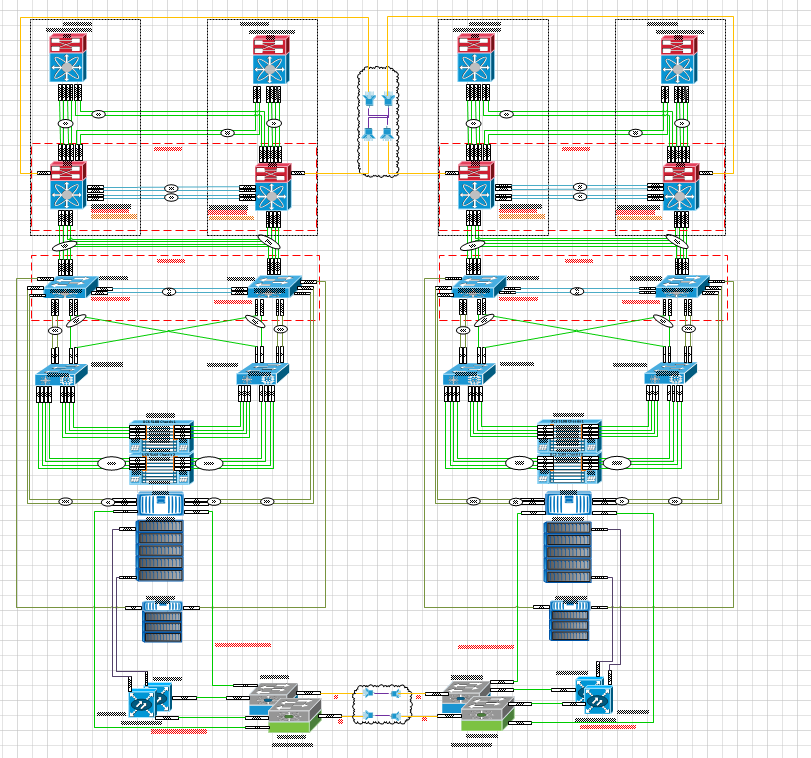
So what exactly happened during the DR test and why did I lose a storage controller? Well I can out my hand up for my part in the failure and the other part comes down to NetApp documentation which is not clear as to what operations needs to be performed and in what sequence. As I’ll discuss later there’s quite a need for them to update their documentation on MetroCluster testing. The main purpose of this post is not to criticise MetroCluster but for me to highlight the mistakes that I made and how they contributed to the failure that occurred and what I would do differently in the future. It’s more of a warning for others to not make the same mistakes I did. Truth be told if the failure occurred on something that wasn’t a MetroCluster I may have been in real trouble and worst of all lost some production data. Thankfully MetroCluster jumped to my rescue on this front. Read More



