
I gave a recap of Cisco Live Melbourne in another post and had intended on providing a detailed look at each of the sessions I attended as part of that post but it became a bit long-winded so I’ve broken it out into separate posts. I’ve broken the sessions down by each day.

Day 1:
TECCOM-2001 – Cisco Unified Computing System
As someone that is working towards CCNA and CCNP in Cisco Data Center this extra technical seminar really was invaluable and opened my eyes up to a lot of areas that were unknown to me. This breakout session was an 8-hour, full-on overview of Cisco UCS, the components that comprise the solution and how it all works together. It wasn’t a deep-dive session however so if you’ve a really good working knowledge of UCS and know what’s under the covers quite well then this session wouldn’t really be for you. In saying that however I think there’s always opportunities to learn something new.

The session was broken down into 6 parts.
- UCS Overview
- Networking
- Storage Best Practices
- UCS Operational Best Practices
- UCS does Security Admin
- UCS Performance Manager
Some of the main takeaways from the session were around the recent Gen 3 releases for the UCS hardware including the Fabric Interconnects and IOMs. They also discussed the new features for UCS Manager 3.1 code base release. Some of the new features of UCSM and the hardware are listed below:
UCS Manager 3.1
- Single code base (covers UCS mini, M-Series and UCS traditional)
- HTML 5 GUI
- End-to-end 40GbE and 16Gb FC with 3rd Gen FI’s
- M series cartridges with Intel Xeon E3 v4 Processors
- UCS mini support for Second Chassis
- New nVidia M6 and M60 GPUs
- New PCIe Base Storage Accelerators
Next Gen Fabric Interconnects:
FI6332:
- 32 x 40GbE QSFP+
- 2.56Tbps switching performance
- IRU & 4 Fans
FI6332-16UP:
- 24x40GbE QSFP+ & 16xUP Ports (1/10GbE or 4/8/16Gb FC)
- 2.43Tbps switching performance
IOM 2304:
- 8 x 40GbE server links & 4 x 40GbE QSFP+ uplinks
- 960Gbps switching performance
- Modular IOM for UCS 5108
Two other notes from this section of the technical session were that the FI6300s requires UCS Manager 3.1(1) and the M-Series is not support on the FI6300’s yet. There was also an overview of the UCS Mini upgrades, the Cloud Scale and Composable Infrastructure (Cisco C3260) and the M-Series. I’ve not had any experience or knowledge of the M-Series modular systems before and I need to do far more reading to understand this much better.
The second part of the session covered MAC pinning and the differences between the IOMs and Mezz cards. (For those that don’t know the IOMs are pass-through and the Mezz are PCIe cards). Once aspect they covered which I hadn’t heard about before was around UDLD (Uni-Directional Link Detection) which monitors the physical connectivity of cables. UDLD is point-to-point and uses echoing from FIs out to neighbouring switches to check availability. It’s complementary to Spanning Tree and is also faster at link detection. UDLD can be set in two modes, default and aggressive. In Default mode UDLD will notify and let spanning tree manage pulling the link down and in Aggressive mode UDLD will bring down link.
The Storage Best Practices looked at the two modes that FIs can be configured to and also the capabilities of both settings. If you’re familiar with UCS then there’s a fair change you’ll know this already. The focus was on FC protocol access via the FIs and how the switching mode changes how the FIs handle traffic.
FC End-Host Mode (NPV mode):
- Switch sees FI as server with loads of HBAs attached
- Connects FI to northbound NPIV enabled FC switch (Cisco/Brocade)
- FCIDs distributed from northbound switch
- DomainIDs, FC switching, FC zoning responsibilities are on northbound switch
FC Switching Mode:
- Connects to Northbound FC switch and normal FC switch (Cisco Only)
- DomainIDs, FC Switching, FCNS handled locally
- UCS Direct connect storage enabled
- UCS local zoning feature possible
{kind=link}
The session also touched on the storage heavy C3260 can be connect to FIs as an appliance port. It’s also possible via UCSM to create LUN policies for external/local storage access. This can be used to carve up the storage pool of the C3260 into usable storage. Once thing I didn’t know what that a LUN needs to have an ID of 0 or 1 in order for boot from SAN to work. It just won’t work otherwise. Top tip right there. During the storage section there was some talk about Cisco’s new HyperFlex platform but most of the details were being withheld until the breakout session on Hyper-Converged Infrastructure later in the week.
The UCS Operational Best Practice session covered off primarily how UCS objects are structured and how they play a part in pools and and policies. For those already familiar with UCS there was nothing new to understand here. However, one small tidbit I walked away with was around pool exhaustion and how UCS recursively looks up to parent organisation until root and even up to the global level if UCS central is deployed or linked. One other note I took about sub-organisations were that they can go to a maximum of 5 levels deep. Most of the valuable information from this session was around the enhancements in latest version of UCSM updates. These were broken down into improvements in firmware upgrade procedures, maintenance policies and monitoring. Most of these enhancements are listed here:
Firmware upgrade improvements:
- Baseline policy for upgrade checks – it checks everything is OK after upgrade
- Fabric evacuation – can be used to test fabric fail-over
- Server firmware auto-sync
- Fault suppression (great for upgrades)
- Fabric High Availability checks
- Automatic UCSM Backup during AutoInstall
Maintenance:
- On Next boot policy added
- Per Fabric Chassis acknowledge
- Reset IOM to Fabric default
- UCSM adapter redundant groups
- Smart call home enhancements
Monitoring:
- UCS Health Monitoring
- I2C statistics and improvements
- UCSM policy to monitor – FI/IOM
- Locator LED for disks
- DIMM backlisting and error reporting (this is a great feature and will help immensely with troubleshooting)
Fabric evacuation can be used to test fabric fail-over before firmware upgrade to ensure bonding of NICs works correctly and ESXi hosts fail-over correctly to second vNIC. There’s also a new tab for health also beside the FSM tab in UCSM.
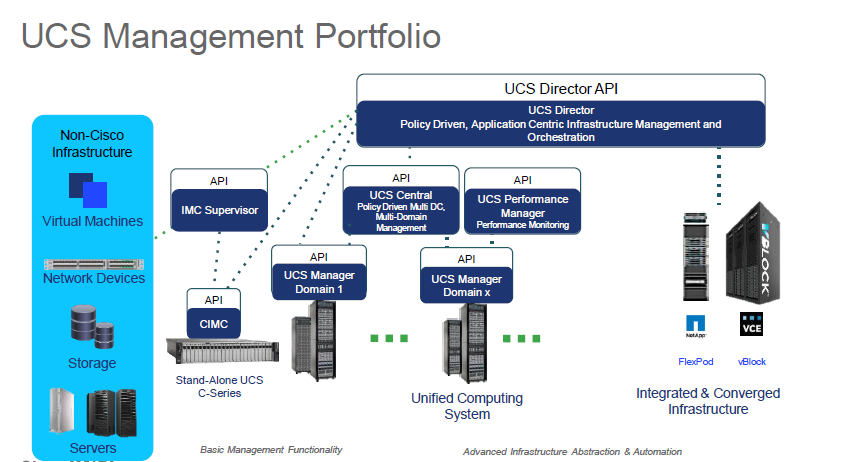
The last two sections of the session I have to admit were not really for me. I don’t know whether it was just because it was late in the day, my mind was elsewhere or that I was just generally tired but I couldn’t focus. The sections on Security within UCSM and UCS Performance Manager may well have been interesting on another day but they just didn’t do anything for me. The information was somewhat basic and I really felt that UCS Performance Manager was really more of a technical sales pitch. I feel the session would have been better served with looking at more high-level over-arching tools for management such as UCS Director rather than a monitoring tool which the vast majority of people are not going to use anyway.
{kind=link}
Overall though this entire technical session was a great learning experience. The presenters were very approachable and I took the opportunity to quiz Chris Dunk in particular about the HyperFlex solution. While I may not attend another UCS technical session again in the future I would definitely consider stumping up the extra cash needed for other technical session which may be more relevant to me then. There’s a lot of options available.
After the sessions were completed I headed down to the World of Solutions opening and wandered around for a bit. As I entered I was offered an array of free drink. Under other circumstances I would have jumped at the chance but I’m currently on a 1-year alcohol sabbatical so I instead floated around the food stand that had the fresh oysters. The World of Solutions was pumping. I didn’t really get into any deep conversations but I did take note of which vendors were present and who I wanted to interrogate more later in the week. I left well before the end of the reception so I could get home early. The next day was planned to be a big day anyway.
Day 2:
BRKCOM-1211, IP Storage Networking Fundamentals
Dr. J Metz ran this session and it was excellent. When I walked in and saw him donning a hat I thought this is going to be interesting, and he didn’t disappoint. The focus of this session was to look at IP storage such as iSCSI, NFS and even block. I’m not going to go into detail on all the things Dr. J mentioned as it’s best to catch that on the Cisco Live 365 and hear him give the run down himself. Some of the key things that be brought up however were that:
- There is no one-size fits all
- Storage only has one job and that’s to give back the correct bit I asked for
- There’s a major difference between how deterministic and non-deterministic traffic is handled
- Deterministic – in-order delivery (lossless)
- Non-deterministic – out-of-order delivery (lossy)
- The more layers the lower the performance (this is a reason object storage is not as quick as block)
- Lots and lots of smaller blocks increases metadata, larger blocks have less metadata but can run into issues with contention.
- Block storage can suffer from I/O Blender issue, NFS doesn’t as each virtual disk has its own connection through the network.

Another interesting bit of advice he highlighted as the type of questions to ask before deploying new storage. This in intrinsic to characterising storage performance and requirements and include
- How much data – now, 5 years and 10 years from now
- How often does it change?
- How quickly do I need it?
- What are the regulatory compliance concerns?
- What sort of workloads will run on the storage
- Write vs Read %
- Random vs Sequential access
- Data vs Metadata %
- Data compressibility
- Block/chunk size
- Metadata command frequency
- Use of asynchronous/compound commands
- The above is intrinsic to characterising storage performance
Dr J also covered the features and characteristics of block, file and object storage in details. Again, it’s worth checking out his presentation for yourself as there’s no way I could add value to what he’s already covered. However, for those that don’t know the differences I’ve added the breakdown for data suitability below.
Block is suitable for:
- Transactional data
- Random read/write
- VMFS volmes
File is suitable for:
- Locking and sharing mechanism for files
- VMFS volumes
- Clustered file system support
- MS AD, SQL, Sharepoint
- Replication and backup workloads
- Deduplication
Object is suitable for:
- Clustered Data
- Web content
- Data Backups
- Archival images
- Multimedia
- Geographically distributed back end
- Replication of back-end storage across multiple DCs
I would highly recommend watching this session for yourself.
GenKey – 1620, Disruption is here, now what?
Generally I’m not a fan of keynote speeches. For me they tend to drag on, are a bit over the top and try to drill up excitement into something that’s not generally exciting. This isn’t a pop at Cisco, it’s the same whichever the vendor conference. A lot of what’s talked about is how great the company is, how they are ahead of the curve with their solutions and also a massive thanks to all the people out there for buying their products. Add in loud music and some funky visuals and you’ve got the essential ingredients covered keynotes for a tech conference. This year Cisco had John Stewart (Senior Vice President of Advanced Security Initiatives, Cisco Security and Trust) present the speech about data, data security and some of the interesting ways that Cisco utilise their technology. Without doubt the most interesting part of the keynote was around the Cisco TACOPS team that provide emergency responses to global disasters. I highly recommend checking out their site and learning a bit more.
On the whole however I did find the keynote a bit of a fizzer and generally lived up to my indifference towards keynotes at large conferences.
PRNTHT-1628, Citrix | Optimizing and Securing Web Applications in a Cisco SDN
This partner session run by Citrix gave an overview of how to best use Citrix Netscaler as part of a SDN solution with Cisco ACI. It was a brief overview and while there’s wasn’t time to go into a full infrastructure design it was enough the whet the appetite and investigate more at another time.
After the Citrix session I had intended on going to a few other breakout sessions but I got talking to Craig Waters from Pure Storage and all my plans for the remainder of the day went out the window. This is the job of conferences. There’s unexpected meetings which means that despite the best planned event you need to be flexible.
Day 3:
BRKACI-2000, ACI Fundamentals
ACI is the next big thing for Cisco and they have been pushing hard to get the message out there. I attended an ACI session about 18 months ago and wrote about that on my Cisco ACI post. A lot has changed since then and I’ve not kept up with everything so I thought a good refresher of the fundamentals was a good idea.
During the session some of the pain-points highlighted in current systems and what sort of use-cases ACI is looking to satisfy. Some of these are:
- Managing heterogenous DCs
- Active/active DC design
- Maintain regulatory compliance
- Balancing agility, performance and security
ACI Fabric Features:
- ACI Spine Layer
- ACI Leaf Layer
- Optimised Traffic Flows
- Decoupling of Endpoint Identity

An APIC is the control powerhouse for the ACI fabric. The APIC is essentially a C-Series server. The steps to getting the fabric operating were defined as:
Step 1:
- Set up and configure APIC
- Add spines and leaves
- Infrastructure VRF has to be set up to allow control plane traffic to be isolated for communication between leaves and spines
Step 2:
Tenant Endpoint addresses are set up. These are called VTEPs (VxLAN Tunnel Endpoint). VTEPs are located on the leafs and the spine is aware of this. As machines move between leaves the VTEP databases are updated and synchronised
Local Layer 2 and Layer 3 takes place directly on a leaf, there’s no need to traverse the spine within the ACI fabric. VLANs used only for tagging purpose in ACI. They play a different role in ACI compared to the existing common vernacular. Even if two ports are on same VLAN within ACI, as routing takes place only at layer 3, these ports can’t see or communicate with each other unless the service policy contract allows it. Bridge Domains in ACI replace Layer 2 VLANs
An ACI App Policy Model comprises:
- Tenant = VDC
- VRF = VRF
- Bridge Domain = Subnet/SVI
- End-Point Group (EPG) = Private VLAN

GenKey-1621, Catalysing Digital Transformation with an Innovation Ecosystem
If you read my previous comments about keynotes speeches then you know they are not really my cup of tea. This keynote turned this view on it’s head. Susie Wei was just brilliant and gave a great run down of how we are all developers, that development is the future of IT and how now is as good a time as any to get started.
Like all keynotes there was a great display and a demo of some great technology. Cisco displayed some of their new collaboration tools, IoT device management and presented to whole solution as part of a disaster management solution. It was pretty impressive.
My one take-away from this event was that development is key to my career as an IT professional.
PRNTHT-1690, NetApp | 3 Deployment Models: 3 Tailored Flash Solutions
Straight after the keynote with Susie Wie I jumped into a session by NetApp on their flash based solutions. I have some decent background knowledge of NetApp solutions but what peaked my interest in this session was the details about NetApp’s recent acquisition, Solidfire. There’s been a lot of confusion around why NetApp purchases another flash storage solution when they already had two existing solutions, the All-Flash FAS and the EF flash E-Series.
Solidfire has been purchases by NetApp to develop not just their sales area to solution providers but also to grow NetApp outside of its core OnTap solutions. It also gives NetApp a large scale out infrastructure that has APIs at its core. There’s also been a good culture fit between the two companies.
Just before the end of the session Sergei (Solidfire speaker) dropped the bomb that Solidfire is going to be rolled into the Flexpod architecture and a CVD will be out for it soon. As a Flexpod customer with NetApp backend storage this is a really interesting decision. Once NFS is ported into Solidfire and the data management features such as SnapMirror work on the platform then it’s really a solution I’ll be willing to consider dropping some cash on.
BRKCLD-2602, Building Your Own Private Cloud
This session was one I was most looking forward to at Cisco Live. It mentioned in the session details that it would cover Cisco UCS Director which is a real interest for me at the moment so I was eager to see how to best use the solution. Serge Charles presented the session and the first thing to roll off his tongue was that ‘it’s all about the applications’. As infrastructure engineers this is something we can sometimes overlook.
The core of the session was looking at how to install and configure UCS Director and define the policies to build out a private cloud management solution. This was a basic overview and was aimed at those that haven’t touched UCS Director before.

Serge also took apart the recently coined term ‘bi-modal’ IT. I’ve read quite a bit about this already but I really liked the way he broke it down into two modes.
- Mode 1 – do what you’re doing today (3 tier apps)
- Mode 2 – cloud scale (NetFlix, Google etc.) – uses microservices

He also looked at the future of on-site infrastructure management and detailed be following as being key:
- Modernise Infrastructure – open + programmable
- Simplify and Automate – policy based
- Build your private cloud – converged solution
Another gem of information from the session was that ‘If you have to do something more than twice in 3 months, you should consider automating it’
BRKCOM-2601, Hyper-Converged Computing
Initally this session was due to focus on Hyper-Converged computing across the board and how they relate to Cisco technology. Just two weeks before Cisco Live started Cisco announced the launch of Cisco HyperFlex. Due to this the content of the session was changed but could only be announced once Cisco Live began. Luckily, Chris Dunk, was one of the presenters on the Day 1 TECCOM session and he gave everyone a heads-up about the change so I was able re-reschedule my sessions.
Hyperconverged from Cisco includes networking, this makes it have an advantage over the other systems as its also included in the cost. However, there were some caveats as mentioned by Chris:
- HCI is not one size fits all.
- It does not solve every business need.
- Cost savings are often over-inflated.
Some of the key highlights of Cisco HyperFlex are:
Complete Hyperconvergence
{kind=link}
Next Gen Data Platform:
- Cisco HX Data Platform
- Data services and storage optimization
Part of a complete DC strategy:
- Cisco ACI
- Cisco One Enterprise Cloud Suite
Controller VMs handles the local storage access and interaction. The CVM (Controller VM) presents out the local disk into a single file-system pool. This is then presented back to hypervisor as NFS datastore.

The log structure file system places newly deduped block at the end of log and updates metadata. The normal process involves reading a block and modifying the block in place following dedupe but the log structure doesn’t need this and can write directly to end of log in new location. Data is striped across disks in all nodes and even different cells on SSD to ensure low overhead on SSDs and increase performance of the HDDs. My guess is that HyperFlex is going to link into M-Series or even the C3260 for storage increases independently.

Erasure coding efficiencies only really come into play at very high levels of scale so it suits object storage. It has a drawback on performance and uses up CPU cycles to bring the required levels of parity. Erasure coding can be offloaded to a hardware card to relieve the CPU cycles. This is not something that is done in HyperFlex.
The deployment steps for HyperFlex are fairly simple as they include Step 0 which involves the configuration and build of your UCS infrastructure. I can foresee some issues with this but Cisco want to retain control of the solution until it gains a solid foundation and grows as a solution. The steps are:
Step 0:
VMware and HX Data Platform installed on servers at factory or reseller before shipping to customer
Installing also involves UCS configuration of UCSM policies and core templates, instantiate and assign service profiles
Step 1:
Rack up servers, power on and add to vCetner
Drag and drop configuration (JSON) file
Step 2:
Provision VMs
Some of the extra information brought up during the session that I think are interesting are:
- There’s be no CVD’s for hyperflex, it shouldn’t need one according to Cisco as it’s a simplified system. There will be solutions documents however.
- ESXi 6.1.0 on the box shipped from the factory. ESXi 5.5 Update 3 and above are also supported.
- UCSM 2.2 (6f) installed on the FIs by default
- IO Visor and VAAIr are VIBs in the hypervisor host.
- IO Visor module presents NFS to ESXi and stripes I/O
- Compress and dedupe occurs from SSD to HDD offload. Write acknowledged immediately by SSD.
- No need to license the IO Visor on existing blade systems.
Replication factor of 3 by default on first release but that requires 5 nodes. It’s possible to deploy 3 nodes with replication factor of 2. I’m not sure why they are pushing the larger of the two options.
BRKDCT-2408, Effective Data Center Troubleshooting Methodologies
This was the last session in a very long day but it was probably the most beneficial to my day-to-day job. Alejandra Sanchez Garcia who used to work for Cisco TAC in Sydney for 7 years so she had a wealth of knowledge on how to troubleshoot issues. The main starting point was breaking down the issue into a fault domain and from there working out the underlying root cause issue. These domains were broken down into Compute, Networking, Storage and Programmability. Once the domain was isolated it’s then possible to drive towards finding a fix to the issue as you’re ignoring noise from other areas.

Understanding the problem is the most important part. If you don’t understand it then you can’t truely fix it as it can re-occur and you’re back to square one again. Alejandra went through 3 scenarios that have been worked on by TAC and interacted with the attendees to resolve the issues. It was an interesting insight into how TAC operates and a look at what methodologies and tools they use to get to the root cause.
Day 4:
BRKCOM-2003, UCS Networking Deep Dive
I knew when I signed up for it that this was going to be a doozie of a session and it was mind-blowingly good. Neehal Daas had such a laid back and relaxed presentation style that it was disarming and the amount of information he dished out was incredible. I’ve always said that networking is my weakest skill in my arsenal so getting up to speed and understanding the networking components of every solution is a key focus.
This session was largely focused on how the networking is split/handled within the UCS platform and how the VICs and IOM work together to create virtual interfaces from the 4 ports on the IOM. 4 x 10Gb KR lanes are available to each half width slot and 8 to a full-width blade. The IOM connects (via KR lanes) to VIC on UCS Blade. Half-width blades only use 2 x 10Gb lanes so you can get a max of 20Gb to blade. Full width can use 4 x 10Gb so they are able to utilise the full 40Gb. In 2208XP however you get 4 x 10Gb to half-width blade as the number of lanes increase due to the extra ports on the IOM.
Fabric link connectivity:
There are two potential fabric link connectivity modes, these are discrete mode and port channel mode. In discrete mode all links between IOM and FI are individual links and pinning is done on the each link. However, in port channel mode all links are grouped together as a port channel and the pinning is done on port channel. Needs 220X IOM to run port-channel mode (2208-XP is recommended). All other IOMs versions have to be in discrete mode.

Server Connectivity:
- VICs – Converged network adapter
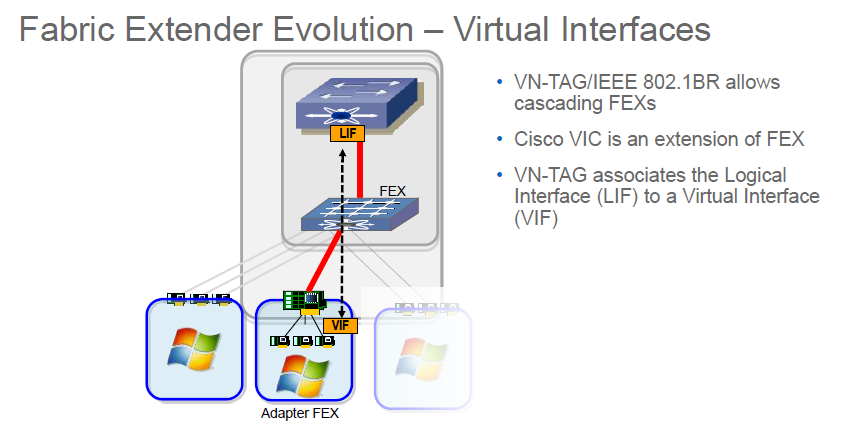
- 3rd Gen VIC use two PCIe bus lanes and this is what gives them extra speed.
- VN-TAG associates a VIF on VM vNIC to LIF on FI
Fabric forwarding:
See the description of Switch-Mode and End-Host mode in TECCOM-2001 – Cisco Unified Computing System above for more detail but the basic concept is that in Switch mode the FI acts like a regular switch and in End-host mode (EHM) there’s no spanning tree. EHM learns the MAC addresses only from server interfaces (e.g like MAC on vNIC on a VM) and the vNICs are pinned to uplink interfaces. This can be discrete or port channel pinning depending on the version of your IOM. In switch mode there’s no pinning on the FIs. Server vNICs follow STP forwarding states.
{kind=link}
Uplink pinning:
UCSM manages the vEth pinning to uplink and pinned uplink must pass VLAN used by vNIC. UCSM periodically redistributes the vEths.
Fabric forwarding – Storage:
In EHM the FI acts as an NPV switch. Having the FI operate in NPV mode means:
- uplinks connect to F port (F port on Storage)
- No domainID consumption
- Zoning performed upstream
VN-TAG:
The secret sauce of how traffic is sent to the correct blade for access via a VM involves the VN-TAG. This tag is inserted into the frame and includes the source and destination virtual interfaces. Without this the FIs would direct traffic to the IOM but it wouldn’t get as far as the blade itself. Below is a diagram showing the IEEE 802.1BR structure and where the VN-Tag fits in.
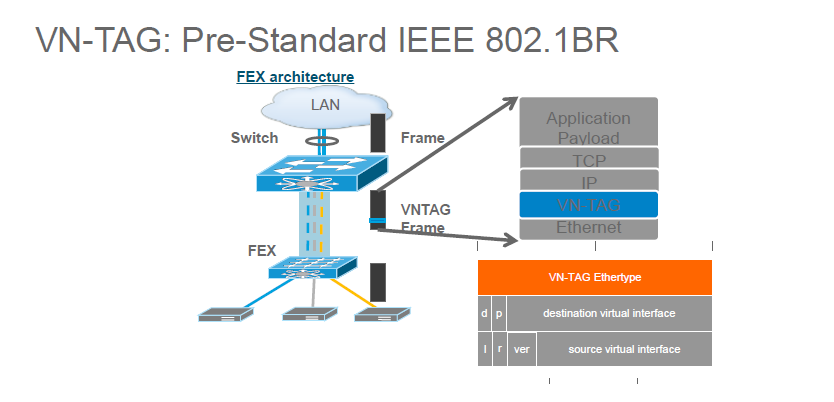
The VN-Tag associates the logical interface on the Fabric Interconnect to the virtual interface on a vNIC of a virtual machine. This ensures traffic can flow between the VM and the outside world.
Neehal provides a number of commands to try on the Fabric interconnects to get more details about the platform. I don’t have a copy of these outputs but they are something I’m going to run within our infrastructure so I can test them out.
show fex details -> you can use this to show FI pinning for IOM
show platform software woodside sts -> woodside is a gen2 ASIC, tiburon is gen3 ASIC
show platform software woodside rate -> shows load rates on IOMs and stats from the perspective of the IOM (in case you need to know B1 = blade controller, C1 = chassis controller in the output)
show platform software enm internal info vlandb id 511 -> this shows which port channel is the sender and listener for broadcast traffic of that VLAN ID
show pinning border-interfaces (This is done on the Nexus 5k) -> shows which vNIC (vEth) is pinned to which Port channel
There was also some information about the new Gen 3 Fabric Interconnects. The F6332 FI (Ethernet only) also runs FCoE. If you need to connect FC interfaces to FIs get the FI6332-UP, otherwise if you’re only accessing IP storage get the FI6332. Also, the new 3rd Gen FIs based on Nexus 9k, 2nd Gen based on Nexus 5k so it has a different ASIC and capabilities.
BRKCOM-2017 – UCS Systems Management Deep-Dive with UCS Foundational Software
The last session of the week was a quality one. The session attendance was small as some people had left early but they missed out on one of the most informative sessions of the week. This was presented by Brad TerEick and have a full run-down of UCSM and its components from a software level. The Software Object model used by Cisco makes Service Profiles possible and provides Cisco the platform to enable stateless servers and to leverage pools and policies for management of hardware. Service Profile Templates form Service Profiles which in turn are just XML settings to define the hardware configurations. The rack servers have IMC APIs which are also quite comprehensive and they are growing over time.
Once excellent bit of information that Brad provided was around an unknown, at least to me, web-based object search within UCSM. You can run queries against visore to find out about your software and hardware within UCS and it can be accessed by adding visore.html at the end of your UCSM browser address: http://uscm_ip_address/visore.html

Under the hood of UCSM there are extensive XML API interfaces which integrate with the GUI and speak to the DME on the back-end. This in turn speaks to the database and the application gateways which are essentially object watchers.
Data Management Engine (DME)
- Entry point of XML API
- Owner of UCS XML database
- Manages config, inventory, health of all end points
- “Queen Bee” of the entire UCS Domain
- Manages and monitors FSM task sequence execution
- FSM Task Sequence = Diff (Desired state from current state)
Application Gateway (AG)
- “worker bee” for a particular endpoint in UCS Domain
- monitors health and status of endpoints in UCS domain
- configures endpoints to desired state configuration as defined by input from DME as the UCS XML database mutates
- executes stimuli for FSM tasks on end point
- executes task on hardware if needed
- executes stimuli for FSM tasks on end point
- reports back to DME the ongoing status of task success or failure
- AGs compare what’s in the software model to what’s on the hardware and resolves the difference
CIM object translation tracks state of objects and can push SNMP northbound or accept a GET command and update the DME.
Another focus of this session was around UCS Central and the added benefit that this can provide to the management of your environment. I currently use UCS Central 1.4 primarily as a backup management tool as it can back up the configurations of the Fabric Interconnects. However it can do a lot more. These are the main areas within UCS Central:
- Information Dashboard – inventory, faults/logs, statistics
- Domain configuration – domain admin settings
- Global Object Repository – IDs, Pools, Service Profiles and templates
- Profile Manager – service profile usage & placement
UCS Central is not an orchestration/automation tool, it’s a manager of managers. It allows for a centralised management location for a number of UCS Domains. UCS Central has it’s own database internally and it also enables a connection to cisco.com for firmware upgrades. The number 1 issue with registration is time synchronization. Make sure UCS Central and UCSM are in lockstep.
You can now group domains in UCS Central (maybe by geographical location) but a domain can only exist in one domain group at a time. You can also now create sub-domain groups so there can be exceptions for different domains but most of the settings are the same for all domains in the domain group. The settings can be controlled/enforced via “System Profile”. This includes the features such as authentication, capability catalog, time zone etc. UCS domain groups are opt in/out. This means that you can choose to use UCS Central to manage the specific policies or use the local UCSM. This is something to consider in particular during upgrades. This wasn’t mentioned during the session but the steps to perform firmware upgrades are different when using UCS Central.
IMC Supervisor is a centralised management tool for C-Series servers and provides hardware profile management and centralised access point. It doesn’t have any of the capabilities of UCS Director but it does look similar. Version 2.0 is right around the corner and should have a number of extra features.
IMC Supervisor features:
- can enable email notification on alerts
- Can perform firmware upgrades
- Can automatically discover new servers
—————————————————————————
And that’s it, that’s a break down of all the sessions I attended. I hope someone finds this useful/helpful. I would recommend getting Cisco Live 365 access to review the sessions in your own time. The presentations are available already and the videos should appear pretty soon. Cisco are usually pretty good at getting the videos uploaded.